Welcome to Tidal Wave, an investment and research newsletter about software, internet, and media businesses. Please subscribe so I can meet Matt Levine one day.
Larry Ellison’s Gospel
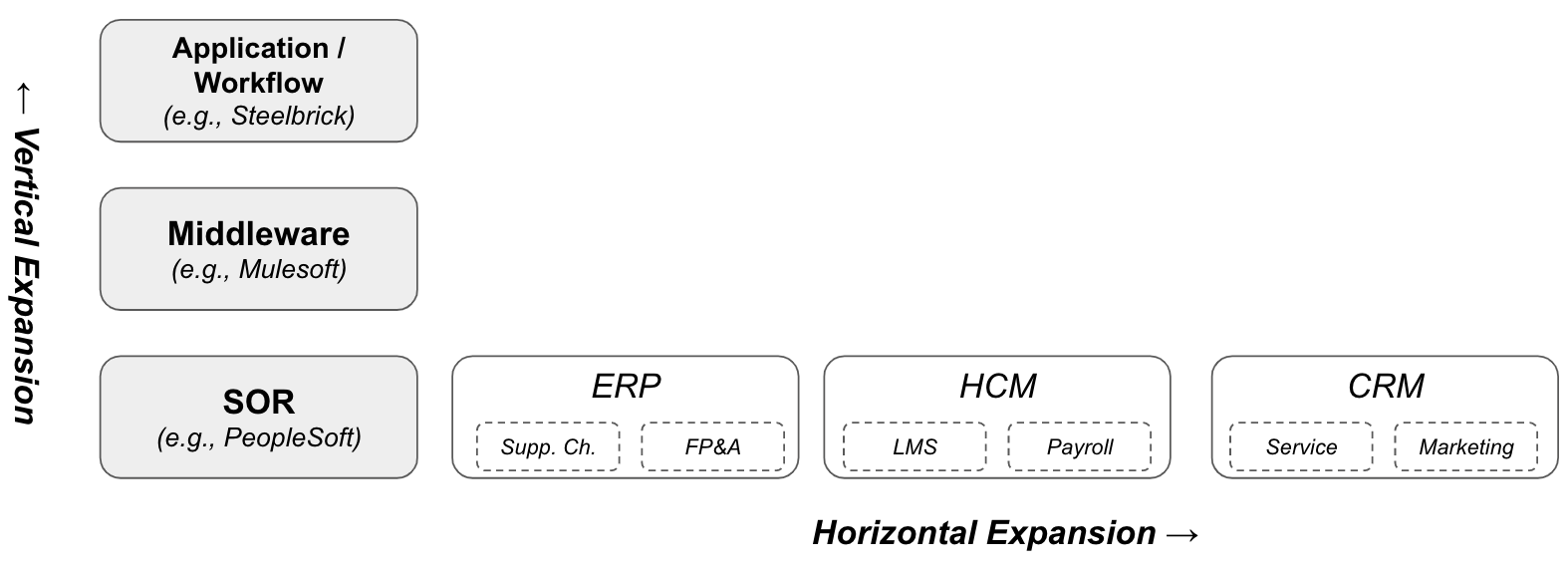
Software companies can be generalized into three categories: systems of record (“SOR”), workflow systems, or middleware tools that help bring these systems together. Few examples of each:
Systems of Record – CRM (Salesforce), ERP (Oracle), HCM (Workday), IT (ServiceNow)
The core systems of record have been CRM (Salesforce), ERP (Oracle), HCM (Workday), and ITSM and the center of gravity in application software has historically been around these SORs. Workflow tools, like those highlighted above, tend to revolve around these SORs. While the SORs have been great investments for investors and extremely sticky with customers, they have a major drawback with regard to end-user UI/UX. Fortunately for the SORs, UI/UX is not always the core buying decision. Workflow software fills the gap in the market by creating software that enables the end-users (e.g., sales reps, customer service agents) to be more productive when it comes to working with or around the SOR.
Thanks for reading Tidal Wave! Subscribe for free to receive new posts and support my work.
The workflow tools exist because the user experience built around the SOR was not always optimized for the automation of tasks and end-user productivity. Many times the core problem the SORs are solving is a database problem. And even when the SORs try to serve the workflow use case there was always a tension between the workflow features the customers want and the SOR’s inherent bias toward their own data models. When SAP builds workflows around their SORs, those SORs are designed with only SAP’s SOR and data model in mind.
Many of 3rd party workflow tools became effectively “Switzerlands” in the software ecosystem, integrate with multiple SORs and help employees complete tasks. The primary task that these workflow tools focus on is the movement and retrieval of data across the systems more efficiently.
As these systems of record mature in their core markets, they typically have to integrate vertically deeper into workflows and expand horizontally into other SORs and sub-SORs1. Both these levers, allow the SORs to persist for a long period of time.
For SORs, vertical expansion can be easier than horizontal expansion. When expanding vertically, the SOR is effectively extending its existing data model. For example, when SAP acquired Concur, they were expending their ERP SOR to subsume a downstream workflow (approvals) but also extending their data model to T&E.
Being caught on the wrong side of the decision by one of these SORs can be treacherous. The workflow vendors that supported fragmented ecosystems with multiple leading SORs tend to be more defensible. But even so, their core TAMs slowly shrink over time as the SORs co-opt some of the features and competition increases from next-generation “best of breed” tools around the incumbent SORs.
In markets where the end customer is using multiple vendors for the core workflow and drawing data from multiple SORs and sub-SORs (e.g., CRM and Martech), building a vertical integration can be borderline impossible or expensive.
Software from different vendors will have different semantics – even something as simple as defining what a “customer” is may differ – different underlying data schemas, which have to be coordinated but will scarcely ever be fully reconciled, and different user interfaces with conflicting design conventions and display elements. Even if the consultants have a prove integration method to link two pieces of software, APIs still have to be specially constructed to pass messages among distinct database schemas, limiting the amount of information that can be extracted as well as duplicating storage requirements.
The natural progression of this train of thought is that SORs should over time leverage their data model to vertically integrate. But the more controversial Ellison conclusion is that these SORs across the business units should be integrated and combined together with the same data model.
The answer to the problems that enterprise application customers were facing, Ellison concluded, lay in doing two things, which he calculated that Oracle alone was capable of. The first was for all of Oracle’s applications to be tightly integrated both with one another and with the database through architecture based on a single shared-data model. The second was to produce the first-ever complete suite of applications that would be capable of automating every aspect of a company’s business, from the traditional ERP, or back-office tasks, such as financials, manufacturing and HR, to the fancy new stuff that included customer relationship management (sales, marketing, and customer support), the supply chain, procurement, and Web stores.
This conclusion (or hypothesis) was somewhat out of self-interest. Ellison’s view was that the database should be the center of this suite and the application suite should revolve around the database. Oracle, the leader in database technology would be the natural vendor for all of an enterprise’s software needs.
Even though Oracle had a variety of challenges executing this strategy, Ellison was broadly right and most software suites have evolved in a similar manner – enterprise software companies start as a core SOR and then expand vertically (via workflows) and horizontally (to other SORs). By the way, he had this vision pre-2000!
Marc Benioff, an Ellison disciple, has been the most public with regard to pursuing this strategy. And like Ellison, Benioff has taken an acquisitive approach to expand his SOR footprint. And like Ellison, Benioff has had challenges executing the consummate with investor expectations.
How Salesforce got here
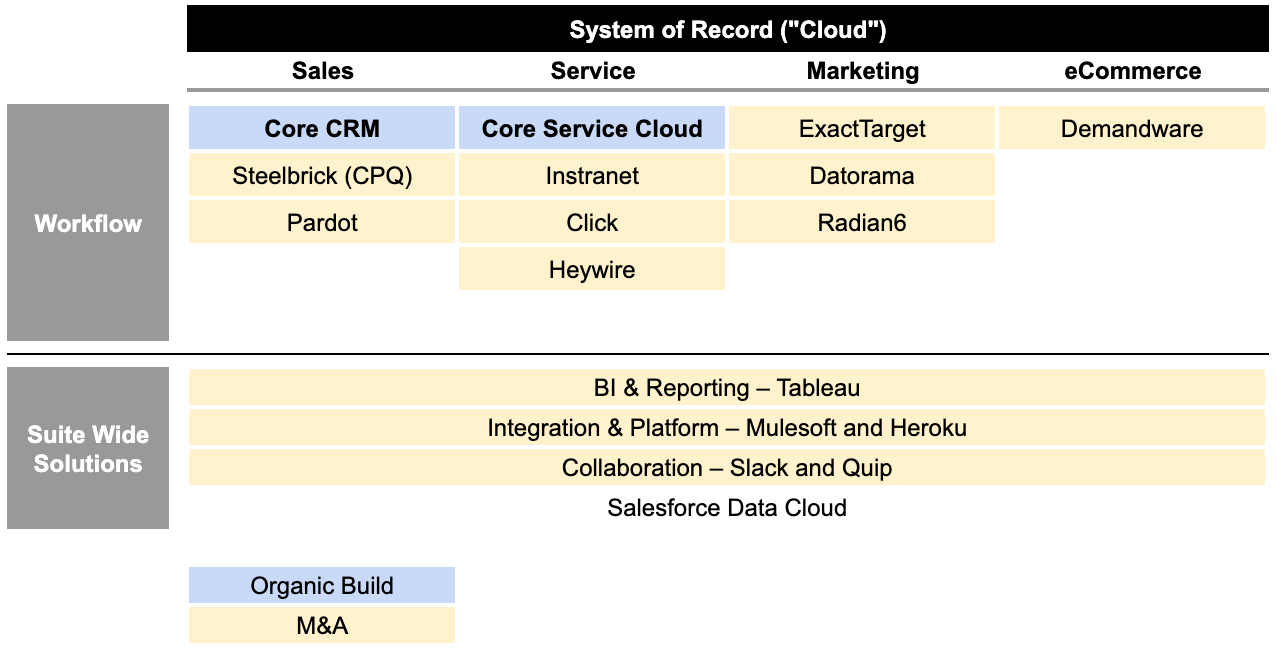
Salesforce started with a sales-focused cloud (CRM) and expanded vertically and horizontally via R&D and acquisitions. The singular goal for Salesforce with these acquisitions was to: (1) create a unified view of the customer and (2) drive automation across the sales and marketing process.
Building the suite has been expensive, both from an M&A perspective and also from the R&D cost to integrate all the different clouds. Acquisitions as the core driver of the strategy has presented a few challenges for Salesforce:
Integrating these different suites and their backends takes a long time.
Customers do not realize the full value of the suite until the integrations are complete because of the disaggregated data models.
Middleservices and data warehouses have evolved to the point where customers could effectively re-create the full sales and marketing stack to be close to Salesforce’s bundle without having to buy the bundle.
As a result of these shortcomings, Salesforce’s primary lever to drive adoption was to focus exclusively on CIO/CDOs and/or concede on price. But more often customers would just stitch a variety of different best-of-breed tools together and create their own data model or framework in the data warehouse.
As a result, for most customers, there has not been a compelling reason to standardize around Salesforce. This is further exacerbated by the fact that Salesforce’s core products are purchased by different teams (sales, marketing, and customer success). The standardization pitch is most effective in the “enterprise” segment, where companies have CIOs, CDOs, etc. that have the mandate to drive the standardization across teams or business units otherwise teams typically choose best of breed tools for their functional group.
Salesforce is not intransigent about this issue and the company has been investing in the backend infrastructure, APIs, and platform to bring these tools together. Arguably, this has been a major drag on the company’s margins and one of the reasons that even as growth has slowed in core Sales and Service Cloud, margins have not inflected as investors have hoped.
Yes, the acquisitions have made the story noisy, but more importantly, the acquisitions consistently moved the ball for the platform, which meant more backend investments.
Those investments have all effectively coalesced around Salesforce’s Genie and Data Cloud. Salesforce brought those products and terms2 to market last 2019/2020.
Importance of the Data Cloud
Salesforce Data Cloud is just a fancy word for the company’s customer data platform. And customer data platform is a fancy word that has all of the relevant customer information from all of a company’s systems in one place. While this sounds relatively simple, this ends up being a very complicated database and orchestration problem3. Companies interact with new and existing customers across multiple teams (sales, marketing, customer service), channels (in-store, online, in-app), devices (mobile, web), and tools.
The information collected at those various points can be different as well. The goal of a CDP is to basically identify Joe Smith across datasets and unify his “profiles” so that when companies interact with him (sales, marketing, customer services), they understand the full context of his interactions with the company.
Because of data privacy concerns and regulations, you cannot hamfist every single data point related to a customer into one database. For example, a cable company likely does not want to include the social security number of all their customers in the database that is used to power the mobile app used by the field service or contractors. To solve this, companies have historically either stitched together these CDPs within in-house solutions and/or used external vendors. These centralized databases have all sorts of compliance support and role-based access controls to prevent any data privacy issues.
On top of doing all of this ingestion and data orchestration, companies have to invest in building dashboards and reporting functionality with a team of data analysts/engineers. All for the “simple” goal of being able to create one unified view of the customer.
Salesforce with its investments in the Data Cloud is attempting to cut out a significant portion of the intermediary layer that goes into creating a unified customer view.
From TrailblazerDx
Salesforce Data Cloud lets you bring in data whether it’s streaming data or batch data at scale, into the platform. And then it lets you create the single source of truth so you know exactly what the customer has done with the business. And then you can actually use that data.
Now the key thing is Data Cloud is not just another data lake or warehouse. It’s an active platform. So that means you can use that insight back into your 360. So that means you can actually call your salesperson, you can create a new service case, you can create personalized ex
What would you do in a normal situation [like this]? You have to take all this data out, put into another lake, run some other program on it, to do AI insights, etc. Not with Data Cloud because we have Einstein built right in. It’s zero ETL and zero copy.
Again, if you have to do this by yourself, what do you have to do? Copy the data into another data warehouse, leave Salesforce, do it all over again, integrate with Tableau. But with the power of the data cloud, with Zero ETL and Zero Copy, Tableau is running live.
The broader objective is that the Data Cloud finally unifies Salesforce’s acquisitions into one data model and platform with support from real-time streaming pipelines. When companies rely on the orchestration or aggregation of data based on APIs or data warehouses, there’s always a lag between data being captured by one system, processed, stored, and retrieved by another system. If you’ve ever stood in front of a Bonobos sales rep waiting awkwardly for their email confirmation for the new account you just created to come through, you know what I’m referring to.
Genie and the Data Cloud basically are creating a real-time single source of truth for companies by leveraging their data streaming services and singular data model.
For those familiar with Salesforce’s story, this is not particularly new. Benioff has been pitching this vision for the past decade and that’s been core to the company’s thesis behind these acquisitions. But the lack of a cohesive data model on the backend has allowed the company to fall short of its potential and more importantly has allowed non-Salesforce tools to co-opt parts of the sales tech stack.
The unified data model should help Salesforce drive more multi-cloud adoption.
At the stage of the company’s lifecycle, the reduction in churn associated with the increase in multi-cloud adoption is going to be very impactful. Today, Salesforce has ~93% gross revenue retention, which is good but not exactly best-in-class, especially for a tool that’s often considered to be mission-critical for companies.
But the unified data view alone is not enough to consolidate and upsell the sales and marketing data stack. The bias continues to be toward best-in-breed tools for each part of the stack. And companies are used to the notion of using a hodgepodge of tools to aggregate and process the data in a cloud data warehouse.
The main carrot Salesforce has to drive this upsell/re-bundling, and where this notion of single customer view really matters, is their automation and AI products.
Automation and Re-Bundling of Software
Salesforce has been on its AI journey for a few years. The simple goal is to automate tasks and provide predictive insights for sales reps and marketers. Per Benioff tradition, it had a very unassuming and easy to understand name, Einstein.
Originally, Einstein primarily helped companies extract and tag information in their CRM and adjacent systems. It would do things like:
Capture customers and deal data from emails, which reduces manual entry for reps.
Turn interaction data into insights i.e., competitors are mentioned.
Score leads and sales opportunities i.e., the likelihood of closing
Predict account churn
The functionality was largely constrained to data retrieval. Einstein saves reps time from route tasks (to be fair, some of which are a function of Salesforce’s design choices). The features largely looked like “out of the box” data science and data engineering, which while impressive did not meaningfully drive value for the average Salesforce customer because the functionality was limited by a few things:
Data silos across the sales and marketing tech stack → improving with Salesforce Data Cloud and companies’ investments in cloud data warehouses and data lakes
Cost of computing and query for ML models → improving with maturation and investment in AI/ML
Salesforce launched the next iteration of this technology at their developer conference, TrailblazerDx. The main focus of the conference was focused on “Einstein GPT”. The product is an extension of the “Einstein AI” that Salesforce launched a few years ago.
Einstein GPT is the world’s first generative AI for CRM. This is important because it is learning from your trusted customer data. You can bring your models and bring your algorithms.
It starts with your customer data. Einstein GPT taps into all the data that you have been building as your single source of truth. And then it uses this data to train using security principals to maintain that secure data access to your data because it’s within the Salesforce trust boundary. This protects the privacy of your PII and it’s purpose-built for Customer360.
Einstein GPT is a gateway where you can use our large language models, or you can bring your LLMs to the process, or you can use the ecosystem for any model that you have already been working with.
The idea is simple, Salesforce can automate a significant portion of the sales reps’ tasks and more specific tasks associated with data extraction and processing. In this example, the processing means taking information that’s in the CRM and creating an output. Automating this aspect of a sales rep’s job is what an LLM is really good at.
Critical for companies is that AI/ML finally gives a tangible output/result for their investments in creating a “single source of truth” that the end business user can see. While the idea of a single source of truth makes a lot of sense, in practice many of Salesforce’s end users have not seen the meaningful benefit of having a tightly integrated system. To date, the benefits have primarily been constrained to reporting and human-driven insights i.e., data analysts.
Beyond reporting and insights, it was hard to justify the business value of aggregating workflows and SORs around one vendor. Yes, there are non-trivial economic vendor consolidation benefits but those benefits are largely the focus of the centralized teams (e.g., finance, data, etc) as opposed to the functional teams using the tools (e.g., sales and customer service). Said more simply, the improvements in AI and LLMs, will finally It finally give companies the incentive to bundle around one SOR, which in this case is Salesforce Data Cloud.
With AI capabilities like LLMs, a sales rep can:
Automate things like customer outreach, research, and service
Create new content
Generate insights without having to leverage a data analyst
Implications for Salesforce and the Ecosystem
For Salesforce, the Data Cloud represents the end of a 10-year investment cycle and the beginning of the company’s re-bundling phase. Tools like Einstein GPT finally provide the tangible business benefits that companies can use to drive vendor consolidation across their teams beyond “it’s less work for the data eng” team.
The likely losers of this are the application and workflow companies that have existed around the Salesforce ecosystem for the last tens of years. Any tool that leveraged Salesforce’s data “plus one” to drive rep productivity is at threat. Plus one refers to the host of companies that created workflow solutions that would combine Salesforce data and data from one other tool (e.g., Outreach, Scratchpad).
Salesforce will likely subsume or make some of these ancillary tools redundant for two reasons: (1) AI-powered workflows will obviate the data coordination problem these companies solved and (2) Salesforce knows that the more workflow and data lives on its platform, the better it can make its models. Over time as Salesforce adopts other AI models (e.g., OpenAI Whisper) and modalities, tools that we likely thought were immune from the threat of Salesforce (e.g., Gong) will likely be under threat.
All these factors, likely lead to Salesforce flexing more pricing power and margin over time than we currently expect4.
Salesforce and Beyond
AI and ML-powered workflows will be automation engines for companies. They will remove a significant percentage of data retrieval and processing that humans currently do when completing tasks at organizations. Most of these tasks and workflows typically have clear constraints and rules, which make them perfect for AI-driven automation. And as per Ellison’s Gospel, having a single system with the same data model that persists through the stack is the best way to drive this automation.
Because of the importance of training data when it comes to creating and improving these models, having a single interface and database is critical for two reasons:
Feedback from humans is critical to fine-tuning LLM models. When a sales rep corrects the output of an email, it is important for the ML model to capture that feedback to help re-train the model.
Not all of a SOR’s data is exposed to 3rd parties. When Salesforce and other software companies build APIs and data access points, they add layers of abstraction, which can obfuscate or loses some of the metadata along the way5.
The result is that Salesforce is best equipped to drive end-to-end workflow automation. This is not dissimilar to the automation that Oracle and Ellison talk about to this day, ~20 years after Softwar.
By using the AI and processes in Fusion ERP cloud, we have been able to eliminate more than 30% of our manual accounting activities. And enabled by Fusion HCM cloud, we have seen employee satisfaction levels soar with all-time high rates for things like hiring and onboarding new employees. We've also made it easier for our managers and employees as Fusion HCM reduces the time needed to complete the talent review process by more than 70%. And separately, we're saving more than 20,000 hours of manager time each year with our accelerated job offer process.
In sales, we're using our front-office cloud platform, augmented with machine learning and our own data cloud, to help our salespeople sell more and sell more quickly. With Marketing Cloud, campaign planning now takes days rather than weeks. And with built-in machine learning, we've seen a doubling in lead conversion. We automatically capture millions of activities in sales cloud each year. And with CPQ cloud, ordering is much faster and easier with over 70% of our transactions fully automated. We needed that to handle the increased volumes of transactions as a result of our customers' move to the cloud. In addition, we've adopted the Gen2 Infrastructure, including Autonomous Database, for our custom apps. Our internal IT costs to run these systems are down by millions while, at the same time, we are adopting more than 100 new features each quarter.
Here at Oracle, we are going to continue using our own cloud technology as an intelligent automation engine and continue to simplify our business model and processes.
In fact, every well-built multi-product software company will have similar benefits.
The story here is not about a mythical “data is the new oil” vision. But rather that having the data in one schema/structure helps drive meaningful automation. The maturation and increasingly lower cost of AI are simply enabling automation. When we talk about automation, it is simply a push towards faster and better data retrieval and process, which is what these new models do really well.
If you’re finding this newsletter interesting, share it with a friend, and consider subscribing if you haven’t already.
For investors, SORs have been great investments because SORs tend to be the stickiest part of the software stack (high switching costs) and they consistently expand their TAM.
As good at marketing as Benioff and the team have been for customers, their obsession with category creation and naming things differently than everyone else has definitely made the investor story hard for people to understand/follow.
Unfortunately for Benioff and many long-term investors in Salesforce, when this does happen, it’ll be a ticker tape parade for the activist investors that got involved in the stock very recently.












Such a great post.