
Databricks (Pre IPO) Primer and a Requiem for Hadoop

Welcome to Tidal Wave, an investment and research newsletter about software, internet, and media businesses. Please subscribe so I can meet Matt Levine one day.
Given this is an investment-focused post, a quick disclaimer: this is not investment advice, and the author may hold positions in the securities discussed.
Databricks has been rumored to go public in 2023 and is one of the few software companies that can likely justify a premium to their last round valuation ($38B) even with the current valuation climate. The company provides a platform that helps companies manage their data, machine learning (“ML”), and artificial intelligence (“AI”) applications.
Given the backdrop and investor enthusiasm (obsession) with AI and ML, the timing probably could not be more fortuitous. A lot of organizations and companies will glom onto the AI and ML theme this year, but Databricks was a company that was purpose-built for managing big data and actualizing the promise of ML. The company’s recent efforts to evangelize a new data paradigm (lakehouse) have, in some ways, put it on a collision course for one of the darlings of the investment community, Snowflake.
But the beginnings were much more humble.
The Birth of Spark
Databricks’ story begins in 2006 with the "The Netflix Prize" Netflix, then primarily a DVD rental company, announced a $1M prize for anyone that could improve the accuracy of the company’s recommendation algorithm by 10%1. Lester Mackey, then an undergrad at Princeton, wanted to compete for the prize, as did 50k+ contestants from all over the world. Mackey would form a team with classmates, David Lin and David Weiss called “The Ensemble,” which would eventually grow to 30 people. The contest would end up lasting three years, and mega teams would form over the globe.
By 2009, people had made improvements to Netflix’s baseline model, but no one had matched the 10% requirement. One of the reasons that the challenge was so difficult was because the tooling at the time to work with Big Data and Machine Learning projects was not robust. And the dataset that Netflix provided was massive; the training dataset had 100M+ ratings on 18K movies from 480K+ users. At this point, Mackey had graduated from Princeton and started his Ph.D. at Berkeley.
Reynold Xin, Databricks Co-Founder: Lester was one of the students at a UC Berkeley AMPLab and he was a very competitive person. And plus, as a PhD student back in Berkeley, he was making $2,000 a month. And the competition has a word of mouth was actually a million dollars.
So Lester really wanted to compete, but he ran into a big problem, which is, it was a pretty sizable dataset. He didn't have the tools to transform them and he didn't have the tools to express the machine-learning algorithms on them.
One of Mackey's Ph.D. classmates was Matei Zahari (Co-Founder of Databricks). Zahari started his Ph.D. at Berkeley in 2007 and was doing work on distributed computing (using a network of computers to solve a computational problem or task). To help Mackey, Zahari built an early version of Spark based on his existing work.
Matei Zahari, Databricks Co-Founder: By seeing the kind of applications that he [Mackey] wanted to run, I started to design a programming model that would make it possible for people like Leicester to develop these applications, and I started working on the Spark Engine, 2009.
Even though only 600 lines of code in the early days, Spark would evolve into a full-fledged processing framework designed for fast and efficient data processing and analytics on large-scale data sets. The early iteration of Spark allowed Mackey and his team members to work with their data more efficiently and iterate faster (more on this later). Mackey and his team were able to use Spark to iterate their solution to Netflix's problem for the final few months of the competition.
Final, because the contest was a race, on June 26, 2009, a competing team out of AT&T, Bellkor, submitted their solution that met Netflix's criteria of improving the baseline model by 10% on a qualifying data set. Per the rules, Mackey's team had 30 days to submit a solution that could beat Bellkor’s. And they did (and just by an inch)! This meant the two teams’ algorithms would be tested against another data set. Both teams submitted the final versions of their algorithms in September, and they tied. Unfortunately for Mackey and Team Ensemble, their submission was 20 minutes past the deadline.
From NYT: The losing team, as it turned out, precisely matched the performance of the winner, but submitted its entry 20 minutes later, just before the final deadline expired. Under contest rules, in the event of a tie, the first team past the post was the winner. “That 20 minutes was worth a million dollars,” Reed Hastings, chief executive of Netflix, said at a news conference in New York.
Though the BerkeleyAMP Lab could not celebrate helping win the Netflix Prize, the development of Spark continued.
From Hadoop to Spark
At the time, Mackey was not the only one struggling with working with large datasets, nor was this the first time Zahari had come across the challenges of working with Big Data.
Zahari: I actually worked pretty early on in 2007 with early users of Hadoop such as Facebook and Yahoo! And so I saw basically across the users there were some common trends. First of all it enabled a new type of application working with these large data volumes on clusters, which was very valuable. But then second what happened is when as soon as people got started they ran into things that the engine couldn't do and the most common ones were actually machine learning which are these iterative computations that make many passes over the same data and interactive queries.
It's hard to talk about Spark without talking about its predecessor, Hadoop.
Hadoop was open-sourced in 2006 and took the (enterprise) world by storm. The pitch was simple, Google, Yahoo, and other tech companies were using data and machine learning to disrupt the world. And with Hadoop, every enterprise could do the same. The messaging was perfectly timed. Because of the proliferation of the internet and mobile, companies had troves of new data about their customers and users. However, companies were constrained by the physical capacity of discs and servers. Hadoop created a file system that could efficiently (by that era’s standards) distribute storage and compute across multiple devices and provided a framework to manage everything. The concept of “Big Data” was effectively enabled by Hadoop.
An ecosystem developed around Hadoop. Companies like Cloudera, HortonWorks, and MapR emerged to commercialize and distribute Hadoop; they would help enterprises deploy Hadoop clusters on-premise and provide support/services for those deployments. The whole ecosystem got massive adoption and attracted a lot of venture funding.
But Hadoop and the ecosystem ran into a few issues that inevitably led to its decline2. The fall was driven by a few things: coupling of storage and compute, programmability, and performance.
Coupling of Storage and Compute: Hadoop was developed during a time when, because of network constraints, the philosophy was to take "compute to the data" As a result, Hadoop tightly coupled storage and compute, and each Hadoop cluster was also a server, which made it expensive for companies to scale their data lakes.
Programmability: it was hard for data scientists to work with Hadoop. The product was based in Java and would require copious lines of code.
Performance: Hadoop was not able to run queries efficiently and, more importantly, for ML use cases, could not do iterative calculations.
Hadoop made it easy for companies to store data, but it was expensive to scale the storage. And companies using Hadoop found that, like other "Big Data" projects, it was one thing to store all the data, it's another thing to actually use the data.
Spark was built to address these shortcomings. Zahari would team up with a few others from the Berkley AMPLab (Ali Ghodsi, Andy Konwinski, Arsalan Tavakoli-Shiraji, Ion Stoica, Patrick Wendell, and Reynold Xin) to build the Spark project, which was open-sourced in 2010. The group would also become the co-founders of Databricks, which would commercialize the open-source Spark project. Ghodsi was the VP of Product in the early days and would become CEO in 2016.
The Spark team made different architectural choices than Hadoop, the technical nuances of which are better explained by others3, but the key things were:
Separation of compute and storage (i.e., cheaper to-scale data storage)
Processed data faster and allowed for faster iterations over the data (i.e., better time to value and could be used for ML application)
Was easier for data scientists to work with
Spark made managing Big Data faster, cheaper, and easier for companies and data scientists. The project was open-sourced in 2010 and took off among the data science and machine learning community. By 2016, Spark had surpassed Hadoop in terms of search queries4.

The post-script on Hadoop isn't that it died. The ecosystem consolidated; Cloudera and Hortonworks merged, and MapR would be acquired by HPE. These vendors' business model was challenged in a world where the cloud was commoditizing Hadoop, and the technology they were providing support was declining. The companies were caught on the wrong end of a technology shift.
And probably did not help because the companies were somewhat captive to the on-premise business models and were late to transition to the cloud. The HortonWorks’ S-1 gives some insight into the company’s thinking at the time:
HortonWorks S-1: Cloud approaches are constrained by performance and compliance limitations. Recent innovations in cloud computing have helped increase business agility and workload efficiency. While big data processing operates optimally when compute and storage are co-located, some cloud computing architectures encourage a decoupling of compute and storage in order to optimize delivery of computing power while minimizing the cost of storage. This means that big data processing must retrieve data from cloud storage separately for any computational analysis, leading to latency, throughput and other scalability challenges. Moreover, corporate and government regulations can inhibit the kinds of datasets enterprises are willing or able to store in the cloud. As a result of these limitations, enterprises are seeking new technologies to collect, store and access higher volumes, velocity and variety of data in a cost-effective manner, and to gain more actionable insight from their increasingly complex and growing data stores. Enterprises need to upgrade their data center architectures to enable them to bring large volumes of data under management and to process and analyze multiple types of data in innovative ways.
It's rumored that Databricks had a sliding door moment similar to the Blockbuster and Netflix story. At one point, the Spark team offered Cloudera and HortonWorks licenses to the project, but they were turned down. Databricks would have to commercialize Spark themselves.
Databricks and the Worst Pitch Deck Ever
In 2013, the group got the opportunity to pitch Databricks to Ben Horowitz and a16z5. Ben Horowitz, recently recounted of the pitch and deck:
“The graphics were terrible,” Horowitz recalls of the deck they showed him. “The ideas were somewhere between patronizing and insane,” he says. “It was a very unprofessional pitch deck compared to what we were used to, for sure.”
Ali Ghodsi, a Databricks cofounder who became CEO in 2016, laughed at the memory of it. “I think our first pitch was really, really bad,” he says.
Fortunately for the team, it wouldn’t matter very much. One of the team members, Berkeley professor Scott Shenker, was friends with Horowitz and had told him he thought cofounder Matei Zaharia was one of the “best distributed systems people out of academia in the last 10 years,” Horowitz recalls.
The pitch deck was indeed very bad by today's standards, from the deck:

But the core ideas of the pitch was simple: (1) Hadoop sucks, and Spark is 100x faster, (2) ML and Big Data will be a rapidly growing market that can be unlocked with Spark, and (3) We built Spark, and we're the best team to commercialize it.
Horowitz (unsurprisingly) was able to see through the poor pitch deck and led a $14M Series A in the company.
Monetizing Spark
Unlike Hadoop, the Apache Spark collaborators commercialized the software themselves, and they had a big advantage compared to its predecessors - the cloud. Around the time Spark took off, companies were beginning to store all of their data and files (unstructured and structured) in the cloud (e.g., AWS S3).
Databricks monetized Apache Spark by offering its customers a managed version of Spark in the cloud (effectively a SaaS offering). The managed offering makes it easy for customers to get started with Spark deployments and not worry about the maintenance and optimization of the clusters. From Day 1, customers can use the Databricks-managed Spark clusters to query, transform and process the data in the data lake (i.e., storage layer). In addition, Databricks provides other SaaS products on top of the Spark engine, including data visualization and data science notebooks.
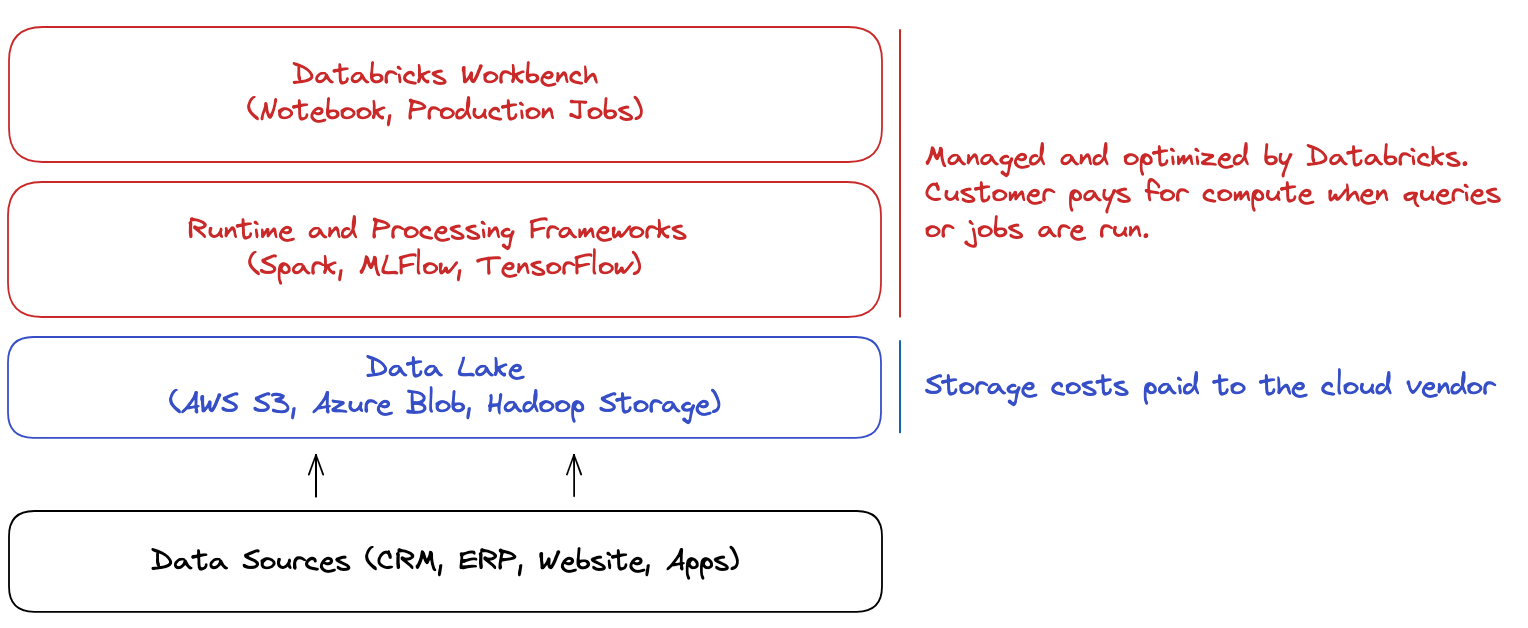
The cloud delivery model allowed Databricks to avoid some of the pitfalls that Cloudera and HortonWorks ran into. Most importantly, the business model was not constrained to offering professional services around someone else’s IP.
Databricks does not, however, charge a subscription fee for its offering. Every time a data scientist runs a query, transforms data, or trains an ML model, some processing power (compute) is required, and Databricks charges for the compute. Similar to Snowflake, Databricks uses cloud infrastructure, so the compute that Databricks charges include a surcharge on top of the cloud vendor’s pricing.
Companies have the option of managing their own Spark cluster to avoid the surcharge, but it comes down to the classic build vs. buy analysis. Managing your own Spark cluster would require some engineering overhead, and more importantly, there’s usually a meaningful performance drop (2-3x) because Databricks, being the core developers of Spark, are naturally the ones that are able to best manage and optimize it.
Databricks, the Data Science and ML Company
Given the focus on the data lake and the team's background/early experiences, the personas Databricks catered to (until recently) were data scientists and ML engineers who were typically working with these large datasets. The primary use cases were (1) large-scale data analysis and (2) machine learning.
A few examples of ML and AI use cases:
Healthcare companies using electronic medical records to discover new treatments
And because time is a flat circle, the streaming service formerly known as HBO, uses Databricks to create its recommendation and personalization algorithms.
To further support the ML engineers, Databricks developed another open-source project, MLFLow. MLFlow is used by data scientists and ML engineers to manage the full machine learning lifecycle. The ML lifecycle is analogous to the software development lifecycle. And just like software engineers have DevOps, ML engineers use MLOps to manage the lifecycle of an ML model from data analysis all the way to model deployment.
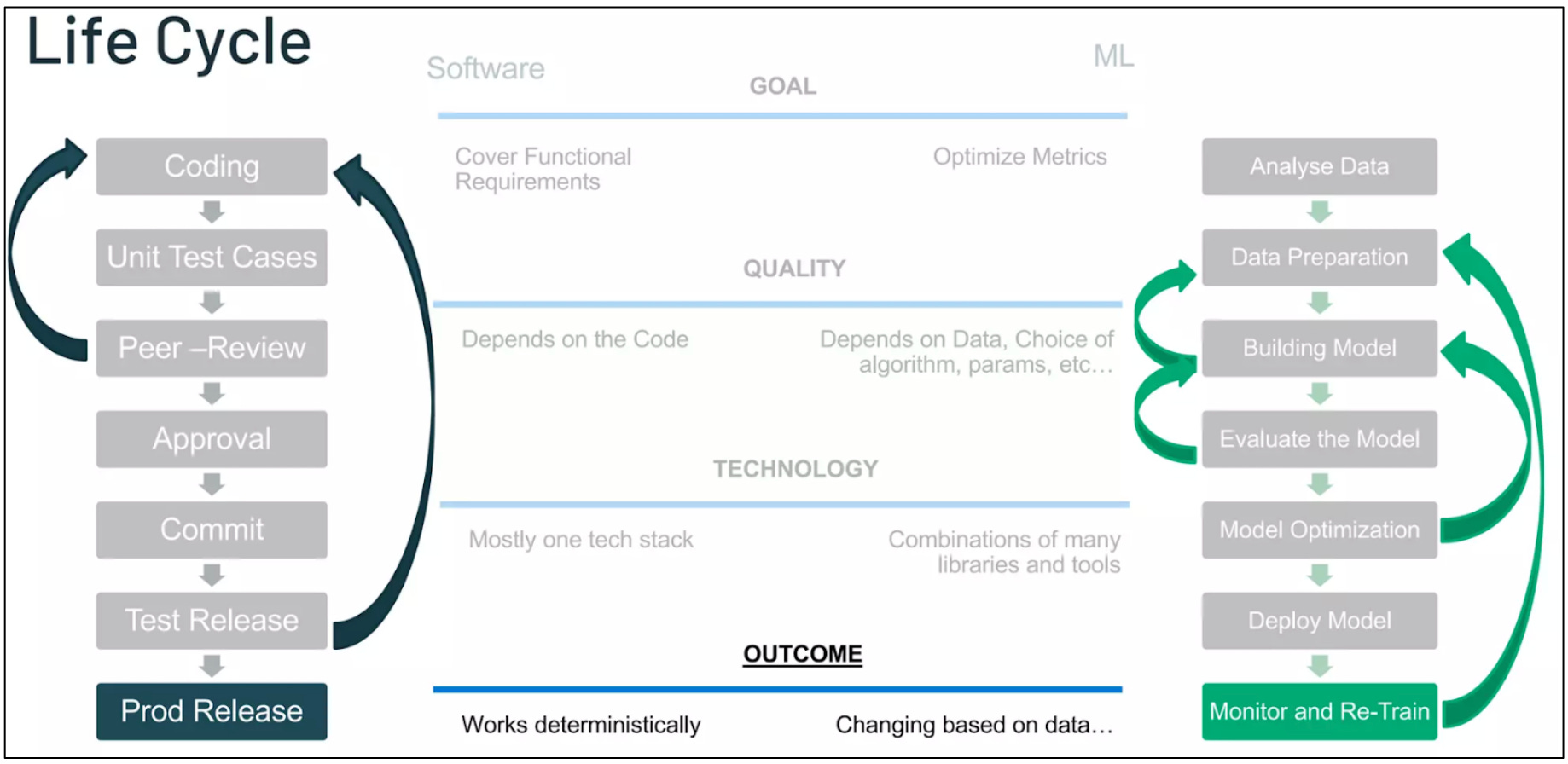
MLFlow provides an interface for engineers to do all of this. There are a host of companies that now specialize in each part of the stack. For Databricks, that’s fine as long as those other vendors work with the MLFlow and Databricks ecosystem, which nearly all do. The goal with MLFlow is for Databricks to make it easier for companies to start, test, and iterate on ML projects on Databricks. Databricks does this to be as cheap and efficient as possible because that means more spend/budget available for compute, the core monetization for the company.

Machine learning applications are compute-intensive (relatively), and Databricks' goal is to commoditize everything that's not directly tied to compute by open-sourcing it and offering a free alternative. Joel Spolsky wrote about this strategy about ~20 years ago:
But something is still going on which very few people in the open source world really understand: a lot of very large public companies, with responsibilities to maximize shareholder value, are investing a lot of money in supporting open source software, usually by paying large teams of programmers to work on it. And that’s what the principle of complements explains.
Once again: demand for a product increases when the price of its complements decreases. In general, a company’s strategic interest is going to be to get the price of their complements as low as possible. The lowest theoretically sustainable price would be the “commodity price” — the price that arises when you have a bunch of competitors offering indistinguishable goods. So:
Smart companies try to commoditize their products’ complements.
If you can do this, demand for your product will increase and you will be able to charge more and make more.
So it is not surprising that Databricks jumped into the LLM discussion recently, promoting the ability to create a ChatGPT clone using their platform for $30.
Two weeks ago, we released Dolly, a large language model (LLM) trained for less than $30 to exhibit ChatGPT-like human interactivity (aka instruction-following). Today, we’re releasing Dolly 2.0, the first open source, instruction-following LLM, fine-tuned on a human-generated instruction dataset licensed for research and commercial use.
Even if it seems somewhat gimmicky, Databricks likely achieved its goal of capturing the attention of CIOs at Fortune 2000 companies that want to cheaply experiment with their own version of the ChatGPT. If enterprises can very cheaply train their own LLMs on Databricks, they can also run all future compute required to train, maintain and improve their own LLMs on Databricks.
While the opportunity to enable companies to do ML and become the de-facto platform for AI/ML is a large opportunity in and of itself, Databricks’ ambitions don't stop there.
Stacking S-Curves, Delta Lake, and Lake House
Databricks’ bread-and-butter persona is the data scientist and ML engineer, but the company wants to expand beyond that, which means they need to evolve their product to serve traditional data warehouse use cases.
To understand why it's helpful to understand the difference between a data warehouse and a data lake. The data lake is a superset of all of an organization’s data, and the data warehouse contains a curated subset of that data designed for BI and visualizations. If an organization decides that certain data from the data lake needs to be in the data warehouse, it'll get cleaned, transformed, and loaded into the data warehouse, where business analysts can query and analyze the data.
But there's a lot of other data that is better left in an unstructured format (text files, video, audio). For example, a healthcare company likely stores patient information (name, age, sex, address, and pre-existing conditions) in a well-defined table in the data warehouse. All of the doctor’s text and audio notes (which are very valuable) are likely stored as files in the data lake.
Analysts at the company can easily query the patient data via SQL or create dashboards to help with questions such as “What is the distribution of ages of our patients?” or “What percent of our patients come to us with diabetes?”. At some point, a data science or ML team may get tasked with creating a predictive model (e.g., the likelihood of diabetes) based on pre-existing conditions and sessions with the physician. The team can now leverage Spark, and the unstructured data sits in the data lake to create the model.

So both data sets and architecture are valuable for the organization. And while big data and AI/ML workloads are rapidly growing, the main way companies and analysts consume and analyze data is via the data warehouse.
Large enterprises (again, think Fortune 2000 and large tech companies) typically have both a data lake and a data warehouse. This creates a fragmented data tech stack, duplication of data, and spending at companies. Here’s Ghodsi talking about this fracturing of data and infrastructure created by the two tech stacks:
As you [companies] get started, you store your data, and you start asking some basic questions. The simplest way to do that and the best stack in the past has been to put your data in a data warehouse and then plug in a BI-tool like Tableau or Power BI. And then you get your dashboards.
As you want to move to the right-hand side and you want to ask about the future then suddenly that stack [data warehouse stack] doesn't work. So you have to completely redo it. Use a different technology stack you store your data in a data lake and then you start using AI technologies on top of it. And you hire different type of people. You hire data scientists for that. You hire analytics engineers or analytics folks and there's this big divide between the two [stacks].
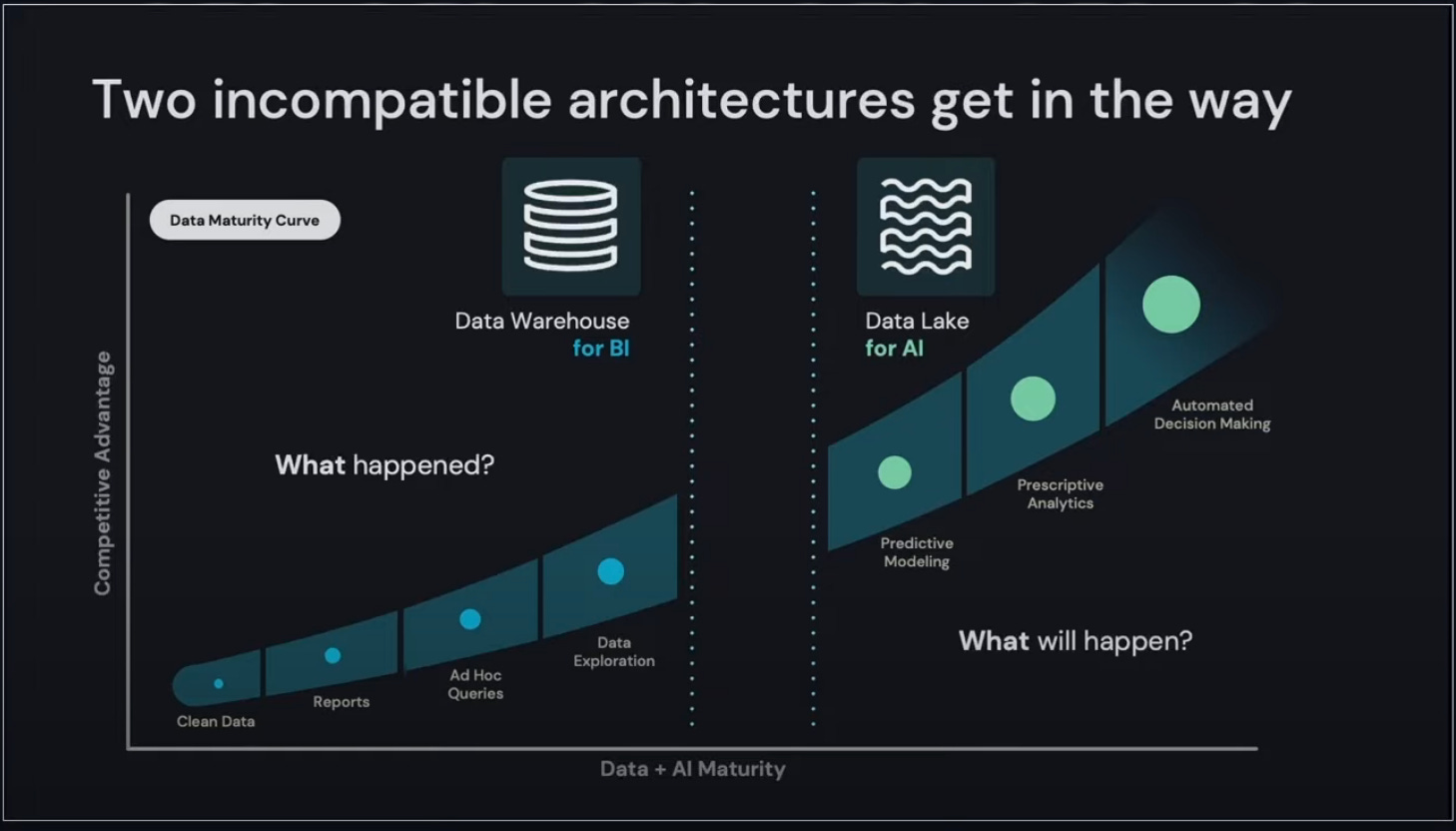
To bridge the gap between the two tech stacks, Databricks, starting in the mid-2010s, began to develop Delta, which brought data warehouse concepts (e.g., ACID transactions, schema enforcement) to the data lake. The idea is to basically combine the best of the data warehouse with the flexibility of the data lake. In 2019, the company started to open-source the project. And in 2020, Databricks announced Delta Lake, offered SQL support, and began to evangelize the concept of a “Lakehouse Platform”.

The Lakehouse Platform was designed to provide the best of both the data lake and the data warehouse. Of course, the natural implication of this is that Databricks is going after the incumbent Data Warehouse vendors (e.g., Snowflake). The company ignited a flamewar last when they published benchmarks that claim that Databricks' lakehouse architecture performs better than Snowflake and other cloud data warehouses.

Their latest research benchmarked Databricks and Snowflake, and found that Databricks was 2.7x faster and 12x better in terms of price performance. This result validated the thesis that data warehouses such as Snowflake become prohibitively expensive as data size increases in production.
Databricks has been rapidly developing full blown data warehousing capabilities directly on data lakes, bringing the best of both worlds in one data architecture dubbed the data lakehouse. We announced our full suite of data warehousing capabilities as Databricks SQL in November 2020. The open question since then has been whether an open architecture based on a lakehouse can provide the performance, speed, and cost of the classic data warehouses. This result proves beyond any doubt that this is possible and achievable by the lakehouse architecture.
Snowflake fired back, and there was a benchmarking war for a few weeks. Snowflake has not exactly sat pretty over the last few years, either. The company released Snowpark, which allows companies to work with data in Snowflake with Python, R, and Scala, which is to appeal to data scientists.
In 2022, Snowflake announced that they have adopted Apache Iceberg, an open-source alternative to Delta Lake, effectively supporting the lakehouse paradigm (with some hedging). Just like Databricks, Snowflake makes money on compute so the company wants to become a platform for data scientists to create and manage ML models as well. Snowflake knows the AI/ML opportunity is massive, from the company’s investor presentation:
 Q2 FY2023 Earnings Report - Software Stack Investing")
Basically, Databricks started with data scientists and ML engineers and is moving towards serving business analysts/users, and Snowflake is moving in the other direction. This is effectively a reflection of the company’s respective backgrounds, Databricks’ team started with machine learning at Berkeley, and Snowflake’s team came from Oracle and the relational database world.
Will Databricks beat out Snowflake for the cloud warehouse mantle? Maybe. But in reality, the market is large enough that it does not devolve into a zero-sum game like what happened with Cloudera and Hadoop. Most likely, in the near term, Databricks and Snowflake will dominate their respective workloads, and the overlap will be at the edges. But there is some risk for Snowflake.

There is the tail-risk that the lakehouse architecture that Databricks is evangelizing ends up being substantial, and Snowflake is completely unable (or refuses) to adapt to the new paradigm. If that happens, it would be the second paradigm that the Databricks’ team kickstarted and used to bludgeon an incumbent.
Financials, Valuation, and Beyond
Databricks is smaller than Snowflake but is (reportedly) growing meaningfully faster than Snowflake. If Databricks can (1) sustain its growth given the demand backdrop for AI and ML workloads and (2) get a slight premium to Snowflake’s current multiple (~15x), it might be one of the few companies that raised last year that can actually IPO at a premium (albeit somewhat modest and excl. IPO dilution).

An IPO like Databricks is probably required to really thaw the late-stage IPO backlog. Regardless of the inevitable timing of an IPO and the outcome of the lakehouse war, the impressive thing about Databricks has been their ability to consistently stack S-Curves. That’s mostly a reflection of the team’s deep bench of technical talent and probably why Horowitz was able to look past the disasterclass of an initial pitch.
If you’re finding this newsletter interesting, share it with a friend, and consider subscribing if you haven’t already.
Always feel free to drop me a line at ardacapital01@gmail.com if there’s anything you’d like to share or have questions about. Again, this is not investment advice, so do your own due diligence.
More detailed discussions about what happened to Hadoop: Talk by Pythian Group, Towards Data Science, and PacketHub
Few resources for that: (1) a detailed tech talk by Zahari and (2) a less technical but detailed discussion of the differences by Simplilearn
The project also has more stars on GitHub as well but not clear if that’s an apples-to-apples comparison because the Star History repo starts in 2016 and shows very few starts for Hadoop.
Unclear if they were approached by Horowitz or the other way around.
Great write up
Awesome work